# Préparer le jeu de données
# Extraire le jeu de données du système d’information de l’organisation
Il est possible que les données que vous souhaitez faire circuler ne soient pas structurées sous la forme d’un jeu de données. Dans cette situation, il est nécessaire de réaliser une extraction des données depuis le système d’information où elles sont stockées. Cette extraction permet d’obtenir un jeu de données structuré, qui ordonne les données en fonction de différentes caractéristiques.
Lorsque vous cherchez à extraire des données d’un système d’information, plusieurs situations peuvent se présenter :
- Le système d’information propose un outil qui permet d’exporter l’ensemble des données depuis le système d’information. Il est nécessaire de sélectionner les données éligibles à la circulation en aval de l’export ;
- Le système d’information propose un outil qui permet d’exporter l’ensemble des données ou de sélectionner un sous ensemble des données à exporter depuis le système d’information ;
- Le système d’information ne prévoit pas d’outil d’exportation des données. Dans ce cas, il est nécessaire de réaliser une opération technique qui permette de réaliser l’export des données. Cette opération est directement liée aux spécificité du système d’information utilisé.
Quel que soit le mode d’export des données, il est recommandé d’automatiser l’opération réalisée afin de faciliter la mise à jour des données publiées. Cette automatisation instaure un processus sur le long terme et fait gagner du temps à l’organisation.
# La structure du jeu de données
Les jeux de données qui ont vocation à circuler seront réutilisés par des acteurs tiers qui ne connaissent pas l’environnement de votre administration. Il est nécessaire de proposer une structure de jeu de données compréhensible et appropriable par tous.
Deux approches sont envisageables :
- La structure de votre jeu de données correspond à un schéma de données existant ;
- La structure de votre jeu de données ne correspond pas à aucun schéma de données existant. Un travail de modélisation est nécessaire en amont de la création du jeu de données.
# Cas 1 - La structure du jeu de données correspond à un schéma de données existant
Lexique : Schéma de données
Un schéma de données est un modèle qui permet de décrire de manière précise et univoque les différents champs et valeurs possibles qui composent un jeu de données.
Il permet notamment de valider qu’un jeu de données se conforme à un schéma, de générer de la documentation automatiquement, de générer des jeux de données d’exemple ou de proposer des formulaires de saisie standardisés. Ces schémas facilitent la montée en qualité et le croisement des données proposées en open data, surtout lorsque plusieurs producteurs de données sont amenés à produire un même jeu de données.
➡️ Consultez notre guide à destination des producteurs de schémas
Les schémas existants peuvent avoir été définis par voie :
- Réglementaire : un modèle de données a été défini de manière réglementaire, par décret ou arrêté. Un schéma est un moyen de faciliter l’adoption de ces modèles par les producteurs de données.Par exemple, le schéma de données relatif à la publication des données essentielles dans la commande publique est fixé par arrêté depuis le 14 avril 2017.
- D’usage : la réutilisation des données décrites par le schéma bénéficie à un grand nombre de réutilisateurs ou de nombreux producteurs sont amenés à utiliser ce schéma.
# Pourquoi utiliser un schéma de données ?
La création d’un jeu de données en conformité avec un schéma de données existant apporte plusieurs bénéfices :
- Le jeu de données créé peut être facilement croisé avec d’autres jeux de données conformes au standard utilisé ;
- L'interopérabilité des données et leur croisement est simplifié ;
- Si le jeu de données que vous créez est une agrégation de plusieurs fichiers produits par différents acteurs, la formalisation et le partage d’un standard de données facilite le travail d’agrégation des données ;
- La formalisation d’un standard de données assure une pérennité des fichiers dans le temps ;
- La documentation d’un standard de données existant est déjà rédigée et accessible.
# Comment identifier un schéma de données déjà existant ?
Le site schema.data.gouv.fr référence une liste de schémas de données existants. Il offre également la possibilité à tout utilisateur de soumettre de nouveaux schémas de données. Lorsque les données que vous souhaitez faire circuler correspondent à un schéma existant, nous vous conseillons de l’appliquer au plus près. Le site schema.data.gouv.fr permet d’intégrer les schémas de données et documentations associées dans d’autres systèmes informatiques.
# Comment produire un jeu de données conforme à un schéma de données ?
Si le jeu de données n’est pas extrait d’un système d’information mais saisi manuellement, l’outil publier.etalab.studio peut assister le processus de production. À partir d’un schéma de données sélectionné, il est possible de saisir les valeurs de chaque information et ainsi produire un fichier exhaustif et conforme.
# Comment valider la conformité d’un jeu de données avec un schéma de données ?
Il est possible de valider la conformité d’un jeu de données à un schéma de données existant grâce à différents outils.
Tout d'abord, il est possible d'indiquer que votre jeu de données correspond à un schéma depuis l'interface d'administration de data.gouv.fr. Lorsque vous déposez ou éditez une ressource, vous pouvez sélectionner le schéma correspondant à vos données dans une liste déroulante.
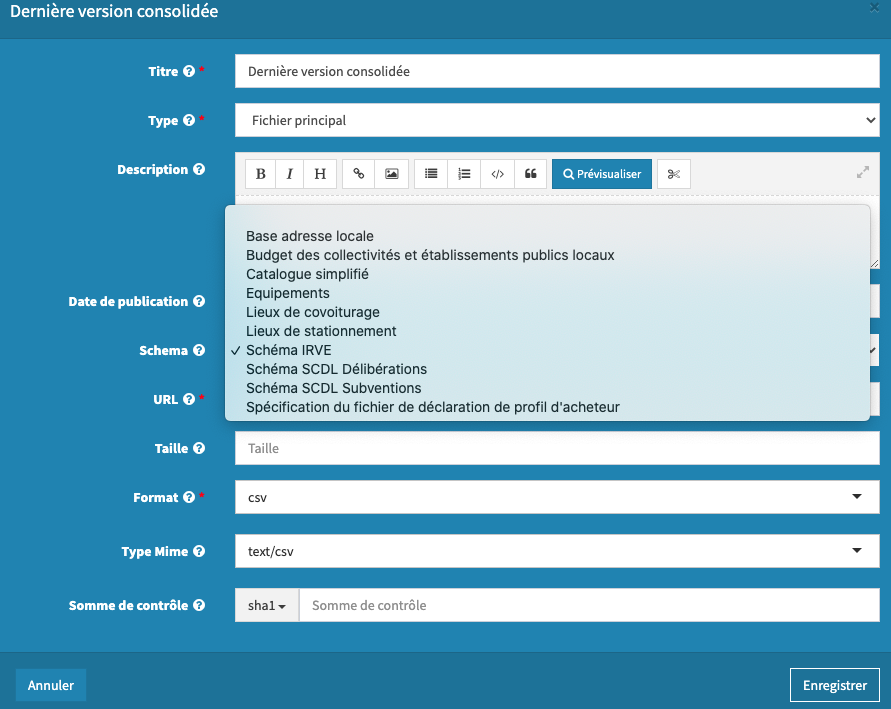
Le fait d'indiquer que votre ressource est censée respecter un schéma permet de bénéficier de vérifications de la qualité des données et d'indiquer aux réutilisateurs que vos données respectent un référentiel.
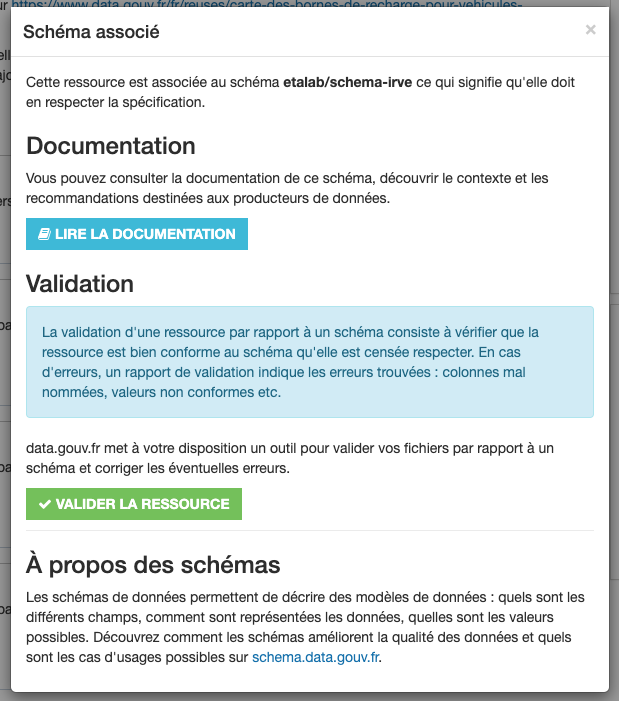
D'autres solutions en dehors de data.gouv.fr existent. Des solutions disponibles en anglais comme goodtables.io ou CSV Lint proposent des validateurs de jeux de données. Enfin, il est possible d’intégrer une fonction de validation d’un jeu directement dans la procédure de publication. C’est le cas pour les données d’adresses locales qui font l’objet d’une validation directement sur le site adresse.data.gouv.fr.
# Cas 2 - La structure du jeu de données ne correspond à aucun schéma de données existant
Si les données que vous souhaitez faire circuler ne correspondent à aucun schéma de données existant, il est nécessaire de réfléchir en amont à la meilleure structure pour vos données.
Tant que les données de votre administration sont dans un environnement logiciel, leur usage reste adapté à des problématiques métiers spécifiques. L’ouverture de ces données en dehors de leur environnement logiciel les émancipent de ce contexte métier. La structure du jeu de données doit alors être pensée en fonction des attentes des réutilisateurs et non plus en fonction des besoins propres à l’organisation.
Les bonnes pratiques à suivre sont les suivantes :
- Occulter l’ensemble des colonnes dont les champs contiennent des données couvertes par un secret légal (se référer au guide juridique pour plus d’information) ;
- Occulter l’ensemble des colonnes dont les champs contiennent des données à caractère personnel dont la publication n’est pas nécessaire à l’information du public (se référer au guide juridique pour plus d’information) ;
- Privilégier la présence de variables pivots. Ces variables proposent des identifiants communs qui permettent de lier plusieurs jeux de données entre eux (ex. Le numéro d’identification SIRET de la base Sirene). Pour plus de détails, consultez la page Lier les données à un référentiel.
Il est également nécessaire de mener une réflexion sur la granularité de votre jeu de données :
- Faut-il proposer des données fines ou agrégées ?
- Faut-il proposer un export quotidien, mensuel, trimestriel ou annuel ?
Ces questions doivent être posées en amont de l’automatisation des exports. Un dialogue avec les réutilisateurs est conseillé afin de comprendre leurs besoins. Certains utilisateurs peuvent souhaiter manipuler des données granulaires tandis que d’autres préfèrent disposer d’agrégats qui permettent une réutilisation simple et rapide. A minima, il est conseillé de proposer un fichier complet unique qui contient l’ensemble des données historiques.
# Le choix du format du jeu de données
Afin que le maximum d’utilisateurs, internes ou externes à votre organisation, puisse s’approprier les données, il est conseillé de les faire circuler dans un format :
- Ouvert : un format ouvert n’impose pas de spécifications techniques qui entraveraient l’exploitation des données (par exemple l’utilisation d’un logiciel payant) ;
- Aisément réutilisable : un format aisément réutilisable sous-entend que toute personne ou machine peut réutiliser facilement le jeu de données ;
- Exploitable par un système de traitement automatisé : un système de traitement automatisé permet de réaliser des opérations par des moyens automatiques, relatifs à l’exploitation des données. Par exemple, un fichier CSV est aisément exploitable par un système de traitement automatisé contrairement à un fichier PDF.
Rappel juridique
Toute organisation de plus de 50 agents chargée d’une mission de service public (les administrations, les collectivités de plus de 3500 habitants et les délégations de service public) est tenue de publier ses jeux de données dans un format ouvert, utilisable et exploitable par un système de traitement automatisé.
Les formats ouverts et communément acceptés sont les suivants :
| Type de données | Formats conseillés | Documentation | Description |
|---|---|---|---|
| Données tabulaires | CSV | Ici | Un fichier CSV est constitué de lignes de données, où chaque champ est séparé par une virgule. Ce format est le standard le plus réutilisable, car ouvert et facilement exploitable par une machine. |
| Données statiques de transport | GTFS/NeTEx | Ici | Le format GTFS est le format le plus utilisé en France par les services de mobilité d’information voyageur. Le format NeTEx est le format de référence européen qui vise l’interopérabilité des données entre États membres. |
| Données géographiques | GeoJSON, Shapefile, MapInfo MIF/MID, MapInfo TAB et GML, pour les vecteurs / ECW, JPEG2000 et GeoTIFF, pour les données pixelisées (raster) | Ici | Les données géographiques sont organisées sous forme d’ensemble de données hiérarchisées. Les formats proposés sont conçus spécifiquement pour être largement exploitables et être intégrés facilement dans des outils de cartographie. |
| Données hiérarchiques | JSON / XML / YAML | indisponible | Les données hiérarchiques décrivent des relations hiérarchiques entre différentes données. Le format JSON est préconisé lorsque les données sont liées entre elles sous forme d’arbres verticaux. |
# Le contenu du jeu
# Le titre du jeu de données
Le titre de votre jeu de données doit pouvoir renseigner n’importe quel réutilisateur sur le contenu du fichier. Pour cela, il est nécessaire de :
- Ne pas donner un titre trop générique qui obligerait le réutilisateur à ouvrir le jeu de données pour comprendre son contenu (Par exemple “liste.csv” ou encore “balance comptable” sans indiquer l’organisation concernée);
- Ne pas donner un titre trop long qui rendrait la manipulation du fichier difficile. Par exemple le titre du jeu de données “Fichier consolidés des données essentielles de la commande publique” est suffisamment générique pour ne pas revenir sur toutes les sources de données utilisées pour agréger le jeu de données ;
- Ne pas donner un titre contenant des accents ou caractères spéciaux qui poseraient des problèmes d’interopérabilité des fichiers ;
- Ne pas donner de titre trop technique issu de nomenclatures métier.
# L’encodage du fichier
L’encodage d’un fichier est la norme utilisée pour coder chaque caractère par une suite de 0 et de 1 compréhensible par une machine. Lorsque l’encodage est mal choisi, le réutilisateur des données est souvent contraint de convertir le fichier, notamment afin de faire apparaître les accents et caractères spéciaux.
Il est conseillé d’utiliser l’encodage UTF-8. Cet encodage permet d’encoder l’ensemble des caractères du répertoire universel de caractères codés (notamment les caractères contenants des accents ou des caractères spéciaux).
# L’entête des colonnes (pour le format tabulaire)
Dans un fichier tabulaire, la première ligne du fichier peut être utilisée pour nommer chaque colonne et donner des informations sur les données associées. Plutôt que d’indiquer “Colonne n°X”, il est conseillé de donner un nom de colonne explicite. Le nom des colonnes doit être sans majuscule, abréviation, accents, ni espaces (préférez le caractère _) afin de faciliter la manipulation des fichiers.
# Le séparateur (pour le format tabulaire)
Dans un fichier tabulaire, le séparateur permet de structurer les données sous forme de cellules. Il est conseillé d’utiliser la virgule comme séparateur.
Séparateurs décimaux
Dans un fichier CSV, la virgule n’est pas considérée comme un séparateur décimal. Si votre fichier contient des valeurs décimales, il est nécessaire d’encapsuler chaque champ entre des guillemets. La plupart des tableurs (Excel, OpenOffice Calc, etc) proposent l’encapsulement des champs entre guillemets. Une seconde solution consiste à convertir l’ensemble des virgules utilisées pour des valeurs décimales par un point.
# Gestion des champs non attribués
Il est possible qu’un champ de votre jeu de données ne soit pas attribué. Il convient de laisser ce champ vide plutôt que d’attribuer la valeur 0. Le zéro correspond à une valeur, qui peut dénaturer le sens de votre fichier.